Ziplist是Redis中为了节约内存空间而实现的顺序性数据结构,通过一系列特殊编码,将数据与其编码信息存储在连续内存中,一个ziplist可以包含多个节点,每个节点可存储一个字节数组或一个整数值,其中对于节点值类型存储还采用了变长的编码方式。具体实现在ziplist.c和ziplist.h文件中。
Redis3.2版本前,ziplist与adlist作为列表对象的底层实现,而3.2后列表对象的底层实现改为quciklist,而ziplist则在quicklist中被应用,除了quicklist,ziplist还被用于zset的底层实现。
数据结构 列表构成 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t)) #define ZIPLIST_END_SIZE (sizeof(uint8_t)) #define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl))) #define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2))) #define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t)))) #define ZIP_END 255 unsigned char *ziplistNew (void ) unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE; unsigned char *zl = zmalloc(bytes); ZIPLIST_BYTES(zl) = intrev32ifbe(bytes); ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE); ZIPLIST_LENGTH(zl) = 0 ; zl[bytes-1 ] = ZIP_END; return zl; }
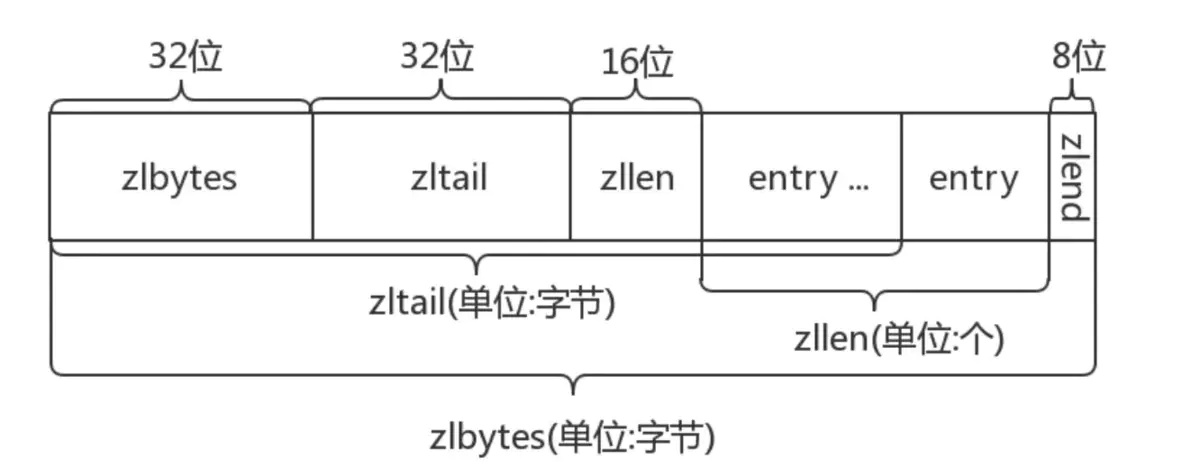
通过初始化函数ziplistNew,可知压缩列表本质上是一个字节数组。初始化ziplist过程,一共申请了11字节的内存空间,其中包括两个uint32_t,一个uint16_t,一个uint8_t。初始化后压缩列表内部内存分布如下
组成部分含义:
zlbytes,表示整个压缩列表占用字节数,包括其自身4字节
zltail,表示到最后一位节点的偏移量,从而能O(1)复杂度获取末尾节点
zllen,表示压缩列表中节点个数。
entry,压缩列表中的每个节点,其中节点长度由保存内容定义
zlend,用于标记压缩列表结尾,使用特殊值255
其中,因为zllen只有两个字节,当压缩列表中节点数大于65534(2^16 - 2)时,都记为65535,而节点的真实数量需要遍历整个压缩列表,此时获取元素个数的时间复杂度从O(1)上升为O(n)。
列表节点构成 列表节点entry,其中逻辑结构如下:
1 <prevlen> <encoding> <content>
prevlen prevlen表示前节点的节点长度,方便反向遍历。根据前一个节点的长度,分为两种情况:
前节点长度小于254时,占用1字节,用来表示前节点长度
前节点长度大于等于254时,占用5字节,其中第1个字节为特殊值0xFE(254),后面4字节用来表示实际长度
如下源码所示,判断节点的第1个字节,如果其小于254,则该值为前节点长度,否则后4字节的值,为前节点长度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #define ZIP_BIG_PREVLEN 254 #define ZIP_DECODE_PREVLENSIZE(ptr, prevlensize) do { \ if ((ptr)[0 ] < ZIP_BIG_PREVLEN) { \ (prevlensize) = 1 ; \ } else { \ (prevlensize) = 5 ; \ } \ } while (0 ); #define ZIP_DECODE_PREVLEN(ptr, prevlensize, prevlen) do { \ ZIP_DECODE_PREVLENSIZE(ptr, prevlensize); \ if ((prevlensize) == 1 ) { \ (prevlen) = (ptr)[0 ]; \ } else if ((prevlensize) == 5 ) { \ assert(sizeof ((prevlen)) == 4 ); \ memcpy (&(prevlen), ((char *)(ptr)) + 1 , 4 ); \ memrev32ifbe(&prevlen); \ } \ } while (0 );
content 节点的content负责保存节点的值,节点值可以是一个字节数组或者整数,值的类型和长度由节点的encoding属性决定
encoding encoding表示当前节点的数据类型以及长度,其中整数节点,encoding均为1字节,而字符串根据长度不同,可能为1,2,5字节。具体的encoding值与数据类型对照表如下
字节值
占用字节
数据长度
特别说明
11000000
1
int16_t类型的整数
11010000
1
int32_t类型的整数
11100000
1
int64_t类型的整数
11110000
1
24位有符号整数
11111110
1
8位有符号整数
1111xxxx
1
0-12的无符号整数
数据存储在encoding部分的后4位,使用0001-1101表示0-12
00xxxxxx
1
<=6bits的字节数组
前两位表示类型,后6位为数据长度
01xxxxxx+<1 bytes>
2
<=14bits的字节数组
前两位表示类型,后14位为数据长度
10000000+<4 bytes>
5
<=32bits的字节数组
前两位表示类型,接着6位留空,后32位为数据长度
zlentry 因为压缩列表本质只是字节数组,为了方便操作,redis还定义了zlentry结构体,操作时,将每个节点包含信息按照一定规则写入zlentry中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 typedef struct zlentry { unsigned int prevrawlensize; unsigned int prevrawlen; unsigned int lensize; unsigned int len; unsigned int headersize; unsigned char encoding; unsigned char *p; } zlentry; void zipEntry (unsigned char *p, zlentry *e) ZIP_DECODE_PREVLEN(p, e->prevrawlensize, e->prevrawlen); ZIP_DECODE_LENGTH(p + e->prevrawlensize, e->encoding, e->lensize, e->len); e->headersize = e->prevrawlensize + e->lensize; e->p = p; }
连锁更新 每个节点会存在prevlen属性,用来记录前置节点的长度,根据前置节点长度还分为两种情况,当长度大于等于254时,占用空间会从1字节扩大到5字节。所谓连锁更新,就是多个长度处于250字节~253字节之间的连续节点,当一个节点更新后,导致下一个节点prevlen由1字节变为5字节,从而导致下下一个节点prevlen值增大,产生连锁反应。因为连锁更新在最坏情况下需要对压缩列表执行N次空间预分配,而每次空间预分配的最坏复杂度为O(n),所以连锁更新的最坏复杂度为O(n^2)。不过,虽然连锁更新的复杂度高,但出现的几率较低,需要多个特殊长度的节点,所以插入删除命令的平均复杂度均为O(n),最坏复杂度为O(n^2)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p) { size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), rawlen, rawlensize; size_t offset, noffset, extra; unsigned char *np; zlentry cur, next; while (p[0 ] != ZIP_END) { zipEntry(p, &cur); rawlen = cur.headersize + cur.len; rawlensize = zipStorePrevEntryLength(NULL ,rawlen); if (p[rawlen] == ZIP_END) break ; zipEntry(p+rawlen, &next); if (next.prevrawlen == rawlen) break ; if (next.prevrawlensize < rawlensize) { offset = p-zl; extra = rawlensize-next.prevrawlensize; zl = ziplistResize(zl,curlen+extra); p = zl+offset; np = p+rawlen; noffset = np-zl; if ((zl+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) != np) { ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+extra); } memmove(np+rawlensize, np+next.prevrawlensize, curlen-noffset-next.prevrawlensize-1 ); zipStorePrevEntryLength(np,rawlen); p += rawlen; curlen += extra; } else { if (next.prevrawlensize > rawlensize) { zipStorePrevEntryLengthLarge(p+rawlen,rawlen); } else { zipStorePrevEntryLength(p+rawlen,rawlen); } break ; } } return zl; } int zipStorePrevEntryLengthLarge (unsigned char *p, unsigned int len) if (p != NULL ) { p[0 ] = ZIP_BIG_PREVLEN; memcpy (p+1 ,&len,sizeof (len)); memrev32ifbe(p+1 ); } return 1 +sizeof (len); } unsigned int zipStorePrevEntryLength (unsigned char *p, unsigned int len) if (p == NULL ) { return (len < ZIP_BIG_PREVLEN) ? 1 : sizeof (len)+1 ; } else { if (len < ZIP_BIG_PREVLEN) { p[0 ] = len; return 1 ; } else { return zipStorePrevEntryLengthLarge(p,len); } } }
小结 ziplist是Redis为了节省内存而自定义的一种特殊编码的顺序性数据结构,与双端链表adlist相比,具有以下特点:
整个ziplist存在一个连续内存中
通过固定内存偏移量获取头节点,保留与尾节点的偏移量zltail,而不像双端链表存储头尾节点
每个节点保留前置节点的长度,从而实现反向遍历,而不像双端链表存储前置节点指针
每个节点采用变长的编码方式,存储字符串或整数值
在特定条件下,ziplist会发生连锁更新,导致增删操作时间复杂度由O(n)变为O(n^2)
参考