Adlist,全称A generic doubly linked list,其实就是Redis中自定义的双端链表,作为一个通用数据结构,主要作用于一些Redis的功能模块,例如RedisServer中关联多个client或者RedisClient中的输出缓冲区等。具体adlist源码实现在adlist.c和adlist.h文件中。
Redis3.2版本前,列表的底层实现是由adlist和ziplist组成,后被quicklist取代,关于quicklist与ziplist后续会单独讲。
数据结构
首先查看头文件adlist.h,对listNode的类型定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
|
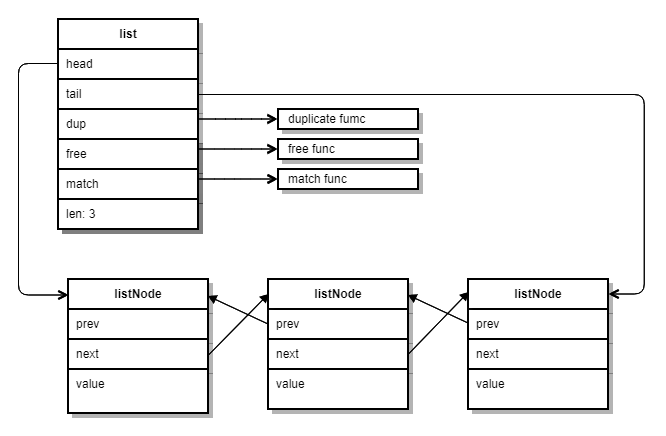
通过前驱节点prev与后驱节点next连接多个listNode,即可实现双端链表,不过adlist中还定义了结构体list,字段含义如下:
- head/tail:分别指向链表的头尾节点,从而更方便获取头尾节点进行操作
- len:保存链表长度,使查询链表长度只需要O(1)时间复杂度
对于表头节点的prev指针,以及表尾节点的next指针都会指向NULL,所以adlist还是一个无环链表。
listNode中使用void *指针保存节点值,对节点值的类型不做限制,从而实现多态链表。而对于不同类型的节点值,需要类型特定函数来处理某些操作,所以list中可自定义三类函数指针,这些函数指针也是通过void *进行保存,对函数类型不做限制。
- dup:自定义复制函数,未定义时,默认的复制方式是同享数据
- free:自定义释放函数,对于一些复杂节点值,可能会需要额外释放内存,未定义时,只释放list本身
- match:自定义比较函数,例如调用listSearchKey时,会调用该函数查看结果是否为true,未定义时,比较数据的指针值
综上,Redis中adlist的结构如下图所示:
迭代器
除了双端链表的基本结构外,adlist.h中还定义了双端链表的迭代器,对于链表遍历操作,都需要通过listIter实例进行,而list则专注于保存节点值。数据结构如下:
1
2
3
4
5
6
7
| #define AL_START_HEAD 0
#define AL_START_TAIL 1
typedef struct listIter {
listNode *next;
int direction;
} listIter;
|
其中,listIter对象根据变量direction,判断遍历方向。以下是listIter对象的创建及使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
listIter *listGetIterator(list *list, int direction)
{
listIter *iter;
if ((iter = zmalloc(sizeof(*iter))) == NULL) return NULL;
if (direction == AL_START_HEAD)
iter->next = list->head;
else
iter->next = list->tail;
iter->direction = direction;
return iter;
}
listNode *listNext(listIter *iter)
{
listNode *current = iter->next;
if (current != NULL) {
if (iter->direction == AL_START_HEAD)
iter->next = current->next;
else
iter->next = current->prev;
}
return current;
}
|
adlist的一些操作
Redis中adlist的创建,添加节点无异于其他双端链表,感兴趣可以自行查看。这里列举一些与dup/free/match函数相关的api源码,加深对这三类函数指针的理解。
清空
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
void listEmpty(list *list)
{
unsigned long len;
listNode *current, *next;
current = list->head;
len = list->len;
while(len--) {
next = current->next;
if (list->free) list->free(current->value);
zfree(current);
current = next;
}
list->head = list->tail = NULL;
list->len = 0;
}
void listRelease(list *list)
{
listEmpty(list);
zfree(list);
}
|
复制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
list *listDup(list *orig)
{
list *copy;
listIter iter;
listNode *node;
if ((copy = listCreate()) == NULL)
return NULL;
copy->dup = orig->dup;
copy->free = orig->free;
copy->match = orig->match;
listRewind(orig, &iter);
while((node = listNext(&iter)) != NULL) {
void *value;
if (copy->dup) {
value = copy->dup(node->value);
if (value == NULL) {
listRelease(copy);
return NULL;
}
} else
value = node->value;
if (listAddNodeTail(copy, value) == NULL) {
listRelease(copy);
return NULL;
}
}
return copy;
}
|
查找
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
listNode *listSearchKey(list *list, void *key)
{
listIter iter;
listNode *node;
listRewind(list, &iter);
while((node = listNext(&iter)) != NULL) {
if (list->match) {
if (list->match(node->value, key)) {
return node;
}
} else {
if (key == node->value) {
return node;
}
}
}
return NULL;
}
|
小结
Redis中实现的双端链表adlist,相同于基础的双端链表,具有以下几个特点:
- 节点值为void *类型,可为任意类型;
- list结构中dup/free/match属性,也为void *类型,可以为链表设置类型特定函数,从而处理不同类型的节点值;
- list结构中head/tail属性,使得获取头尾节点以只需要O(1)的时间复杂度,并且可以正序/倒序访问;
- list结构中len属性,使得获取链表长度只需要O(1)的时间复杂度;
- 链表表头节点的prev指针与表尾节点next都指向NULL,从而adlist为无环链表;
- 链表的迭代操作由迭代器listIter对象完成。
参考